Home | Bug Bounty | Threat Modeling | SAST | Services | About me | Blog
There has been a lot of discussions recently about the future of bug bounties because of AI capabilities, particularly for open source projects:
Rapidly improving AI capabilities and the volume of reports they
generate are pushing well beyond their limits existing vulnerability
disclosure programs.
Yet, if you have been convinced for years of
the value of your bug bounty, the rational decision should be trying to
optimize it, not to suspend it.
The domino effect we are observing is telling another story. Let’s try to figure out the assumptions it could be based on:
When faced with a dead end, the rational decision is to take a step
back before considering giving up.
And Einstein suggests spending
more time on understanding the context: “If I had an hour to solve a
problem I’d spend 55 minutes thinking about the problem and 5 minutes
thinking about solutions.”
Doing so leads to the following conclusion: “find me what is wrong
security wise” is a very poor problem definition.
Different actors
will have distinct interpretations, particularly when they are driven by
divergent incentives.
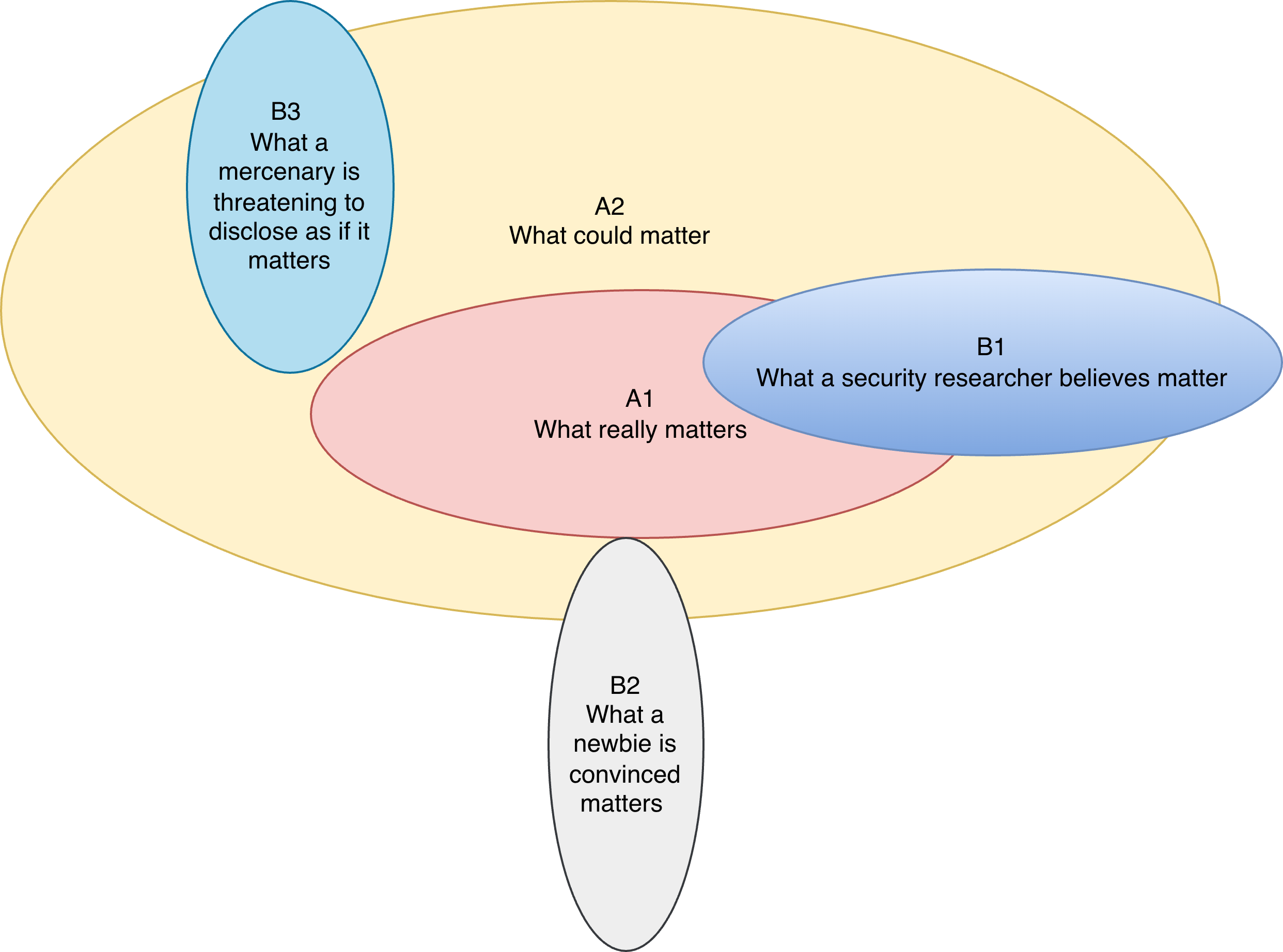
Illustration of the distinct implicit scopes
In an ideal world, we can define with clear boundaries the area A1 containing only the security issues that are worth fixing for the business.
In the real world, it is more than challenging to come up with such boundaries. To be on the safe side, not to call it FOMO because security teams have in their DNA to try reducing risk as much as possible, but also because it requires less effort, the area A2 ends up being much wider. And somehow gets defined iteratively by fine tuning the scope with reports that are obviously not in A1, and for those who are borderline by clarifying the threat model. (By looking at how restrictive the scope is you can have a clue on which teams spent more time on this topic).
On the other side researchers, depending on their experience and motivations, will come up with their own borders for areas B1, B2 and B3.
With AI improvements, curl was first flooded by B2 reports and now by
B1 findings.
But B1 noise was already a concern for programs with
significant payouts, big amounts also incentivizing B3 reports. Open
source projects were somehow immune because they just didn’t have the
budget. (Paid security researchers could present some findings at major
conferences, but their effort was capped by the budget their employer
was willing to trade against reputation building.)
With the wave of
venture capital in AI security startups, aggressive marketing strategies
from some of those vendors are now burning huge volumes of tokens to
discover “critical” open source vulnerabilties in exchange of media
coverage.
How could we focus only on area A1?
And what
could we do if area A1 discovery rate is still greater than remediation
throughput?
Reducing scope to make A2 closer to A1 has already been
mentioned.
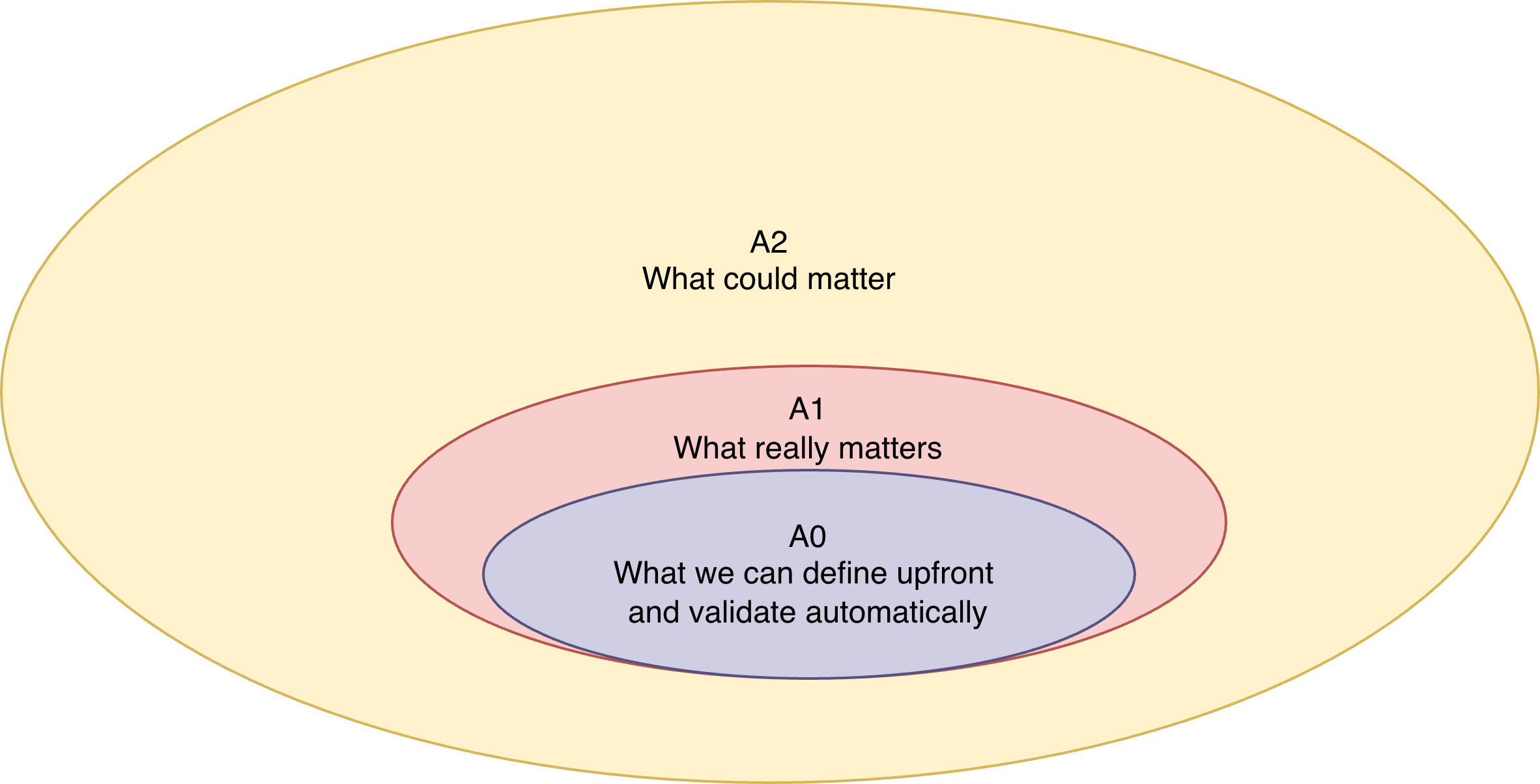
What about trying, as in this other diagram, to start
with a deliberately more restricted scope A0 but where findings are by
design impactful and can be proven automatically?
And in fact the security world is already familiar with those constraints: the same apply to Capture The Flag events.
So why not deploy a version of the software and include flags
that a researcher is not supposed to be able to read?
It
could be data of another user, an environment variable, accessing a
file, etc. Anything that should not happen given your threat model.
By focusing first on impact, vulnerability type later, severity can be
decided upfront (and also payouts).
The researcher only has to share
the flag, gets confirmation it is valid and only then provides details
in a report.
For sure this solution is not perfect, nor a one-size-fits-all
approach. But could it be more efficient and more effective than the
status quo?
Here is a short and non exhaustive list balancing the
pros and cons.
Pros:
Cons:
It’s time to move from theory to practice.
Following the advice from Scott Behrens to solve
by default, the flagADA tool has
been implemented (with Claude Code giving a boost).
Its main goal is
to make it easy enough for some open source projects to test this flag
approach.
Because only data can prove if this other path makes sense in
practice, I am looking for volunteers.
Do not
hesitate to send a message at
flagada@appsecmatters.com, communicate publicly via the
github repo or
share this post.